Insiders Say DeepSeek V4 Will Beat Claude and ChatGPT at Coding, Launch Within Weeks
DeepSeek's upcoming V4 model could outperform Claude and ChatGPT in coding tasks, according to insiders—with its purported release nearing.
In brief
- DeepSeek V4 could drop within weeks, targeting elite-level coding performance.
- Insiders claim it could beat Claude and ChatGPT on long-context code tasks.
- Developers are already hyped ahead of a potential disruption.
DeepSeek is reportedly planning to drop its V4 model around mid-February, and if internal tests are any indication, Silicon Valley's AI giants should be nervous.
The Hangzhou-based AI startup could be targeting a release around February 17—Lunar New Year, naturally—with a model specifically engineered for coding tasks, according to The Information. People with direct knowledge of the project claim V4 outperforms both Anthropic's Claude and OpenAI's GPT series in internal benchmarks, particularly when handling extremely long code prompts.
Of course, no benchmark or information about the model has been publicly shared, so it is impossible to directly verify such claims. DeepSeek hasn't confirmed the rumors either.
Still, the developer community isn't waiting for official word. Reddit's r/DeepSeek and r/LocalLLaMA are already heating up, users are stockpiling API credits, and enthusiasts on X have been quick to share their predictions that V4 could cement DeepSeek's position as the scrappy underdog that refuses to play by Silicon Valley's billion-dollar rules.
Anthropic blocked Claude subs in third-party apps like OpenCode, and reportedly cut off xAI and OpenAI access.
Claude and Claude Code are great, but not 10x better yet. This will only push other labs to move faster on their coding models/agents.
DeepSeek V4 is rumored to drop…
— Yuchen Jin (@Yuchenj_UW) January 9, 2026
This wouldn't be DeepSeek's first disruption. When the company released its R1 reasoning model in January 2025, it triggered a $1 trillion sell-off in global markets.
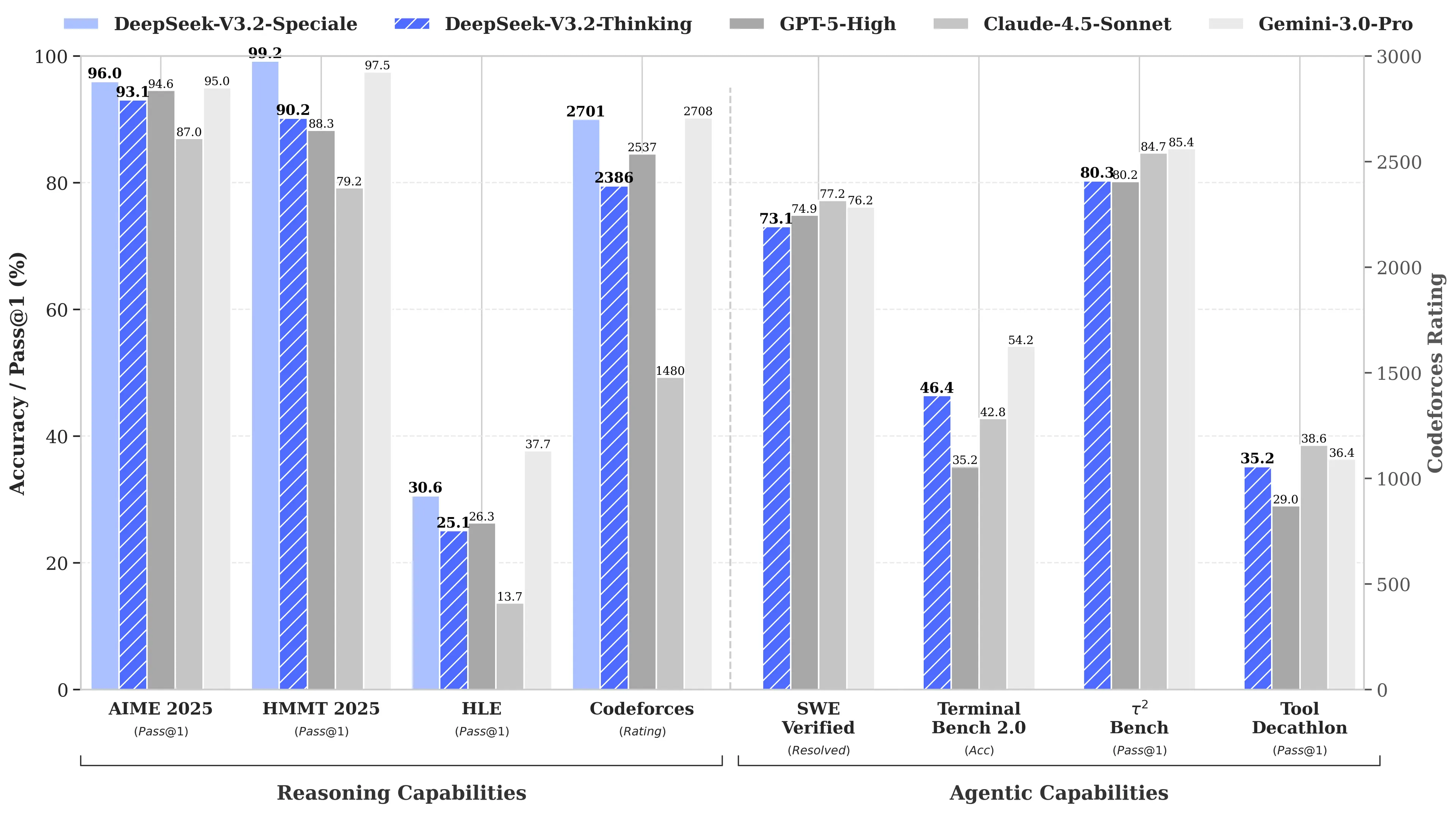
The reason? DeepSeek's R1 matched OpenAI's o1 model on math and reasoning benchmarks despite reportedly costing just $6 million to develop—roughly 68 times cheaper than what competitors were spending. Its V3 model later hit 90.2% on the MATH-500 benchmark, blowing past Claude's 78.3% and the recent update “V3.2 Speciale” improved its performance even more.