Nvidia's CUDA Tile examined: AI giant releases programming style for Rubin, Feynman, and beyond — tensor-native execution model lays the foundation for Blackwell and beyond
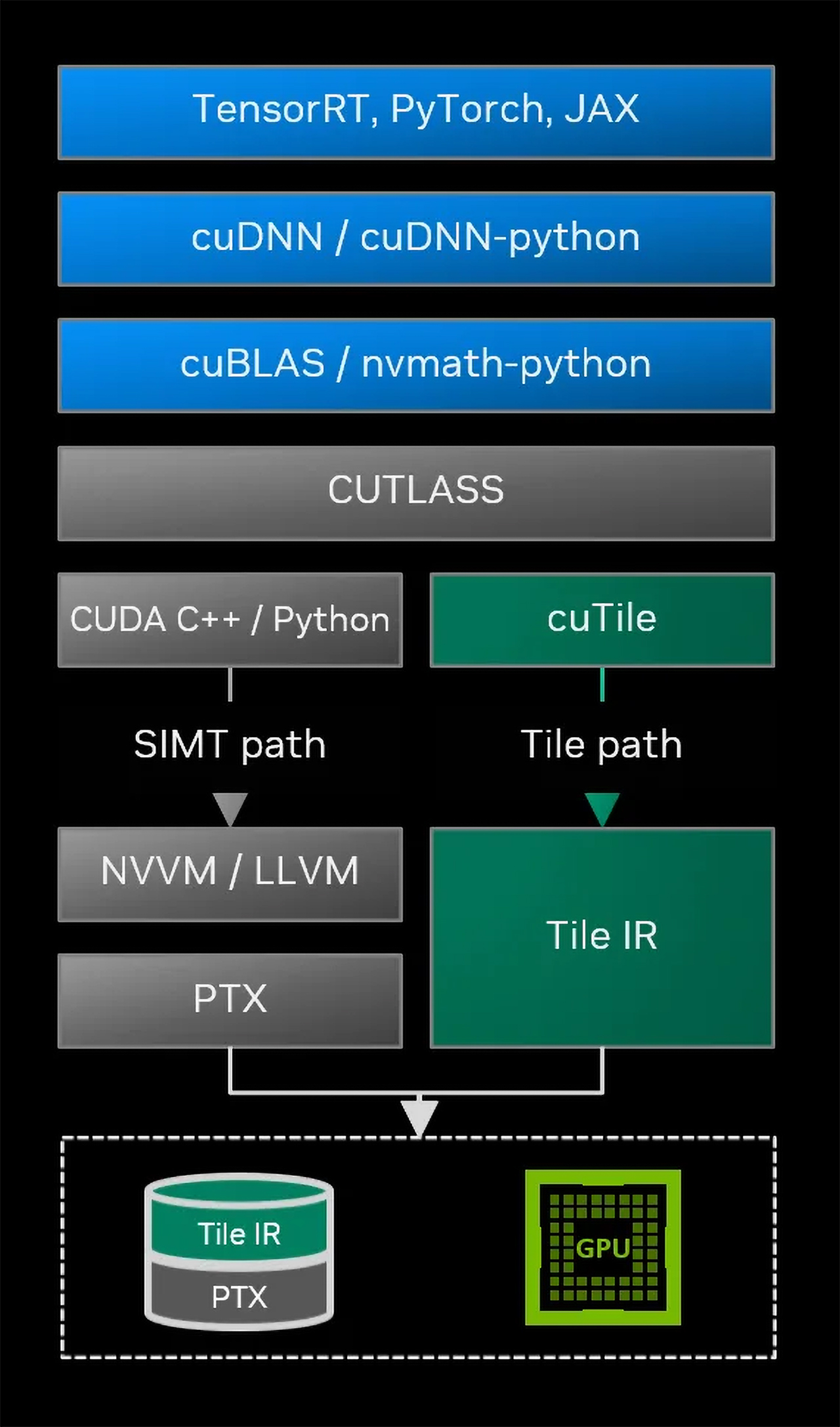
Nvidia's CUDA 13.1 introduces CUDA Tile, a new tile-centric programming path that elevates GPU kernel development above SIMT. The innovation aligns CUDA with the tensor-native execution model of Blackwell-class GPUs, and lays the software foundation for future architectures built around increasingly specialized compute and data-movement engines rather than thread-level parallelism.
(Image credit: Nvidia)
This month, Nvidia rolled out what might be one of the most important updates for its CUDA GPU software stack in years. The new CUDA 13.1 release introduces the CUDA Tile programming path, which elevates kernel development above the single-instruction, multiple-thread (SIMT) execution model, and aligns it with the tensor-heavy execution model of Blackwell-class processors and their successors.
By shifting to structured data blocks, or tiles, Nvidia is changing how developers design GPU workloads, setting the stage for next-generation architectures that will incorporate more specialized compute accelerators and therefore depend less on thread-level parallelism.
Tom's Hardware Premium Roadmaps
SIMT vs. Tiles
Before proceeding, it is worth clarifying that the fundamental difference between the traditional CUDA programming model and the new CUDA Tile is not in capabilities, but in what programmers control. In the original CUDA model, programming is based on SIMT (single-instruction, multiple-thread) execution. The developer explicitly decomposes the problem into threads and thread blocks, chooses grid and block dimensions, manages synchronization, and carefully designs memory access patterns to match the GPU's architecture. Performance depends heavily on low-level decisions such as warp usage, shared-memory tiling, register usage, and the explicit use of tensor-core instructions or libraries. In short, the programmer controls how the computation is executed on the hardware.

(Image credit: Nvidia)
CUDA Tile shifts programming to a tile-centric abstraction. The developer describes computations in terms of operations on tiles — structured blocks of data such as submatrices — without specifying threads, warps, or execution order. Then the compiler and runtime automatically map those tile operations onto threads, tensor cores, tensor memory accelerators (TMA), and the GPU memory hierarchy. This means the programmer focuses on what computation should happen to the data, while CUDA determines how it runs efficiently on the hardware, which ensures performance scalability across GPU generations, starting with Blackwell and extending to future architectures.
A strategic pivot in the CUDA Model
But why introduce such significant changes at the CUDA level? There are several motives behind the move: drastic architectural changes in GPUs, and the way modern GPU workloads operate. Firstly, AI, simulation, and technical computing no longer revolve around scalar operations: they rely on dense tensor math. Secondly, Nvidia's recent hardware has also followed the same trajectory, integrating tensor cores and TMAs as core architectural enhancements. Thirdly, both tensor cores and TMAs differ significantly between architectures.